The tl;dr is that search got really good suddenly and really easy to build because of AI.
For instance, this is the search experience I recently made for my side project website Braggoscope.
Braggoscope is my unofficial directory of BBC Radio 4’s show In Our Time. There are over 1,000 episodes on all kinds of topics, like the Greek Myths or the Evolution of Teeth or Romeo & Juliet. It’s a static site built on GitHub Pages.
I can search for “Jupiter” and the episode about Jupiter comes back back.
But check it out! I can also search for “the biggest planet” and the same episode is at the top of the list. Semantic search like this used to be hard to build, and now get it for free by indexing our documents as embeddings and storing them in a vector database.
We’ll walk through building this search engine right now.
What are embeddings? What’s a vector database?
Embedding models are an adjacent technology to large language models.
Using an embedding model, you can convert any string of text (a word, a phrase, a paragraph, a document) into a vector. Think of an embedding vector as a coordinate in semantic space. Like an x,y vector is a coordinate in 2D space, an embedding vector is a coordinate in a much larger space, usually about 1,000 dimensions.
Indexing a set of documents is a matter of converting them all into vectors, using an embedding model, and storing them in a vector database.
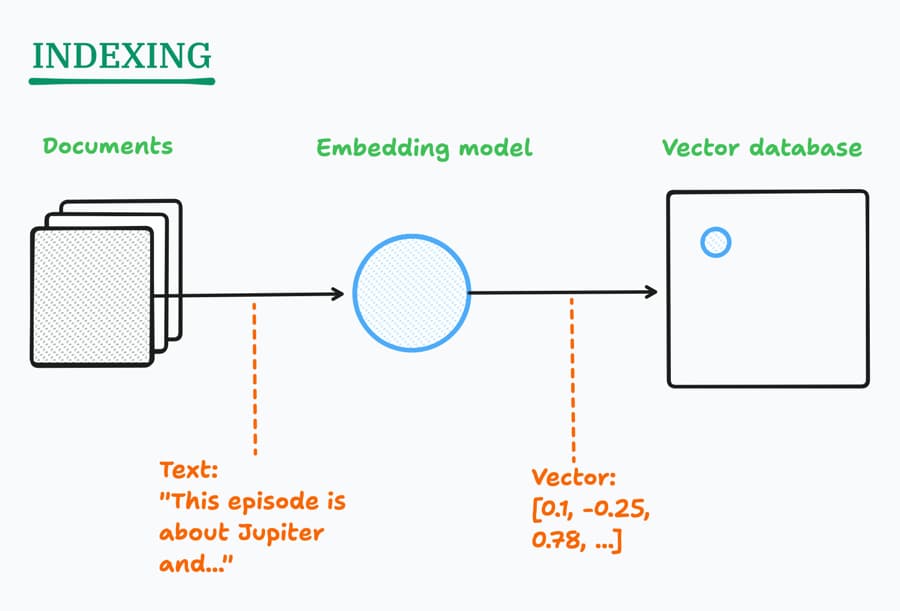
These vectors have a curious property: nearby vectors mean approximately the same thing. Distance in embedding space = semantic similarity.
So querying the index is merely getting the embedding vector of the user’s search query, and looking for nearest neighbour documents. (This is why we need a vector database: traditional databases are really slow at calculating “nearest”.)
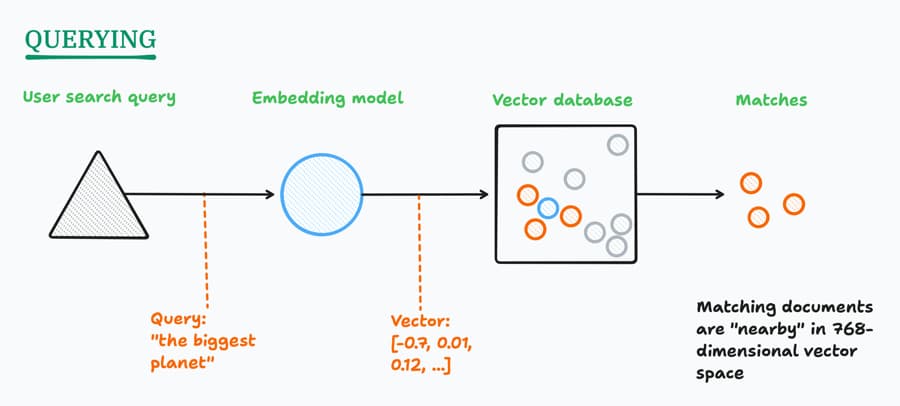
Embeddings can be used for much more besides search, as Simon Willison explains in his excellent article: Embeddings: What they are and why they matter.
New PartyKit features: a vector database and an embedding model
PartyKit has just added first-class integrations for both a vector database and running AI models, including an embedding model.
Not too long ago, Cloudflare announced its own hosted vector database called Vectorize. Another Cloudflare product, Workers AI, hosts several machine learning models.
PartyKit’s simple API makes it easy to use these Cloudflare products. Here are the PartyKit AI docs.
This is handy because now I can combine them with other PartyKit features and still keep everything really easy to manage.
Ok let’s build the search engine.
We’ll build a search engine with an admin UI and a query API
I’ll show you how I built this search engine for Braggoscope. It’s straightforward enough that you should be able to apply it to your own project.
I’ll also show you how to run the code locally.
Here’s the plan:
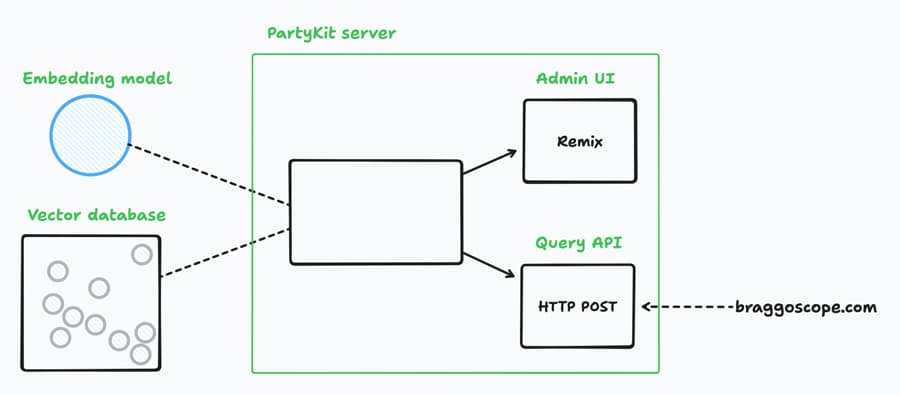
Step 1: A PartyKit project with a web UI
We’re going to want a basic UI to manage and test the search engine.
Although PartyKit is mostly for writing realtime, stateful micro-servers, it can also host websites.
I usually do this with the PartyKit x Remix Starter Template (Remix is a full-stack web framework using React).
Following the instructions in that GitHub repo, I broke ground by typing:
npx create-remix@latest ./braggoscope-search --template partykit/remix-starter
npm install partykit-ai # install the PartyKit AI library
If you’re following along, then grab the code instead:
git clone https://github.com/genmon/braggoscope-search
cd braggoscope-search
npm install
I’m not going to run through how to create this app because this is just the management UI. You can read the Remix app code in app/ — it just provides a web UI to test the search engine.
You can visit my deployed app here: braggoscope-search.genmon.partykit.dev.
Step 2: Setup
We need a vector database and access to the AI features for the embedding model!
In the project directory, type:
# You’ll be asked to log in to PartyKit
npx partykit vectorize create braggoscope-index --preset @cf/baai/bge-base-en-v1.5
Here we’re creating the vector database and calling it braggoscope-index. The --preset flag sets the appropriate number of dimensions for the embedding model we’ll use in the next step.
Hint The Vectorize commands are the same as those provided by Cloudflare’s Wrangler CLI tool. We’re running them through the PartyKit CLI so that PartyKit can manage the database for us. Read the docs for the complete Vectorize CLI or use npx partykit vectorize --help.
Now add these lines to your partykit.json config file (or check that they’re present if you already have the code):
{
// ...
"parties": {
"search": "party/search.ts",
},
"vectorize": {
"searchIndex": "braggoscope-index",
},
"ai": true,
}
We’ll create a new PartyKit server to manage indexing and querying. That’s what we’re going to write in search.ts (it doesn’t exist yet).
The vectorize property lets us refer to our new vector database as searchIndex from within PartyKit. We could have chosen any name, and we can have multiple indexes.
The ai property is a flag that means we’ll have access to the embedding model.
Let’s make a minimal PartyKit server in party/search.ts:
import type * as Party from "partykit/server";
import { Ai } from "partykit-ai";
export default class SearchServer implements Party.Server {
ai: Ai;
constructor(public room: Party.Room) {
this.ai = new Ai(room.context.ai);
}
}
Step 3. Indexing!
We need to get all our documents into the vector database.
Braggoscope is a static site — but it is built from a database, so I can output all kinds of files in the build step. So it now generates a single file that lists all the pages and the content we want to index. Here’s an extract:
[
{
"id": "p0038x9h",
"title": "The Speed of Light",
"published": "2006-11-30",
"permalink": "/2006/11/30/the-speed-of-light.html",
"description": "Melvyn Bragg and guests discuss the speed of light. ...",
},
// ...and so on for another 1,000+ episodes
]
If you like you can see the whole file here: www.braggoscope.com/episodes.json
Now have a look at the finished PartyKit server in the repo: search.ts.
Here’s the entire code of the indexing function.
async index(episodes: Episode[]) {
// Get embeddings for episodes
const { data: embeddings } = await this.ai.run(
"@cf/baai/bge-base-en-v1.5",
{
text: episodes.map((episode) => episode.description),
}
);
// Vectorize uses vector objects. Combine the episodes list with the embeddings
const vectors = episodes.map((episode, i) => ({
id: episode.id,
values: embeddings[i],
metadata: {
title: episode.title,
published: episode.published,
permalink: episode.permalink,
},
}));
// Upsert the embeddings into the database
await this.room.context.vectorize.searchIndex.upsert(vectors);
}
What’s happening here?
this.ai.run(...)is how we use Cloudflare Workers AI.@cf/baai/bge-base-en-v1.5is the embedding model that converts text to vectors. It’s all the same syntax as using Cloudflare directly, so read the Workers AI text embeddings docs for more.- Vectorize expects records in a particular shape with an ID, the vector itself in
values, and arbitrary metadata. The metadata is returned when we query, later, so we can use that to store the title and permalink for each episode. - Finally we access our vector database (using the name set in
partykit.jsonabove) and use upsert to insert (or replace) vectors. Here are the Vectorize API docs over at Cloudflare.
In all of this we’re batching the calls for efficiency.
Actually, as you’ll see, there’s a little boilerplate in search.ts around the indexer…
There’s a web-based admin UI and indexing is kicked off when you tap that Create Index button. (For minimal security, you have to provide a secret key in the URL). Then we step through the episodes in pages, calling index() for each page. Progress is broadcasted over a websocket and displayed in the web UI.
For example, what I do is set my secret key in .env:
echo "BRAGGOSCOPE_SEARCH_ADMIN_KEY=dummy-key" > .env
And then I visit braggoscope-search.genmon.partykit.dev/admin?key=dummy-key to create the index (only with my actual key in the URL).
You can also do this locally:
npm run dev
# then visit: http://127.0.0.1:1999/admin?key=dummy-key
Indexing takes a few minutes.
Step 4. Querying
Looking at search.ts again, here’s the code to run a query.
async search(query: string) {
// Get the embedding for the query
const { data: embeddings } = await this.ai.run(
"@cf/baai/bge-base-en-v1.5",
{
text: [query],
}
);
// Search the index for the query vector
const nearest: any = await this.room.context.vectorize.searchIndex.query(
embeddings[0],
{
topK: 15,
returnValues: false,
returnMetadata: true,
}
);
// Convert to a form useful to the client
const found: Found[] = nearest.matches.map((match: any) => ({
id: match.vectorId,
...match.vector.metadata,
score: match.score,
}));
return found;
}
Breaking it down:
- The query is converted to a vector embedding, as before.
- We find the nearest vectors in the database with
searchIndex.query(...)— this also gives us the metadata stored during indexing. - Finally we convert the result to a useful shape and return.
Let’s add an API so we can see it in action.
Step 5. Adding a query API, and testing it
Go back to search.ts and look for the onRequest function. Mostly the code there is to handle CORS headers so the PartyKit server can accept HTTP POST requests from other domains, such as braggoscope.com itself. (See: Cross-Origin Resource Sharing at mdn web docs).
The relevant code is pretty minimal:
if (req.method === "POST") {
const { query } = (await req.json()) as any;
const found = await this.search(query);
return Response.json({ episodes: found }, { status: 200, headers: CORS });
}
And we can test it from the command line…
curl \
--json '{"query": "the biggest planet"}' \
http://braggoscope-search.genmon.partykit.dev/parties/search/api
If you’ve cloned the braggoscope-search repo and followed along by creating the vector database, and populating it with the indexing step, you can even do this when developing locally:
npm run dev
curl \
--json '{"query": "the biggest planet"}' \
http://127.0.0.1:1999/parties/search/api
Finally: Integration
You can try this search engine standalone, as I’ve included a test UI in the Remix app. Try it out here.
If you’re up and running locally, and the curl above was successful, then the test UI will work for you to:
npm run dev
# then visit: http://127.0.0.1:1999
The final step is to wire up an input box on your website to call the query API, and display results in a dropdown using your favourite framework. I won’t go into detail here.
But to see the final result, go to braggoscope.com — then tap Search in the top nav. That uses the HTTP POST API that we just built.
And we’re done!
Lines of code, including boilerplate and other niceties: 162. Not bad.
Vector databases are useful beyond search
Really good search is nice to have, sure, but how else are vector databases used?
It turns out that they also underpin RAG, or Retrieval-Augmented Generation. RAG is the primary technique for making AI chatbots that don’t hallucinate, and copilot-like experiences where the AI provides relevant help.
Invented by Meta in September 2020, RAG is now a fundamental pattern, using search to dynamically construct prompts based on user context. Nvidia explains more.
And when you combine that with PartyKit’s easy-to-spin-up real-time, multiplayer capabilities…
…well this feels like a great new building block to have.
Want to get started?
Check the PartyKit docs for…
- PartyKit AI — to use Vectorize and several AI models.
- PartyKit x Remix Starter Kit — for a full-stack web app with a PartyKit server.
Any questions or feedback, do join us on our Discord or say hi on Twitter.
Enjoy!